Тестирование — одна из областей, где AI-агенты изменили не набор инструментов, а экономику процесса. Playwright, Cypress, Jest, pytest работают как и раньше. Что изменилось — стоимость написания и поддержки тестов. По данным ThinkSys QA Trends Report 2026, AI-self-healing сокращает затраты на поддержку тестов до 70%, тесты становятся частью того же артефакта, что и код, а практика test-driven development, которая двадцать лет оставалась нишевой, возвращается как стандартный способ работы с AI-агентами.

Цифра 17% взята из исследования 82 447 GitHub-проектов — это срез до массового прихода AI-ассистентов. В ближайшие пару лет она должна значительно вырасти просто за счёт смены инструментария: раньше тесты писали из-под палки, теперь для агента тест — самый точный способ сформулировать задание, и писать их становится проще, чем работать без них.
Параллельно размывается граница между разработчиком и QA-инженером. В 2026 тесты всё чаще пишутся в той же IDE и теми же агентами, что и прикладной код. QA-инженер в новой реальности больше похож на SRE для качества, чем на автоматизатора. Расходы на тестирование смещаются с людей на инфраструктуру — облачные окружения, observability-платформы, токены для агентных циклов. Это проще масштабировать и проще бюджетировать.
Какие бывают тесты
Тесты в современной продуктовой разработке делятся по уровням пирамиды и по типу проверки.
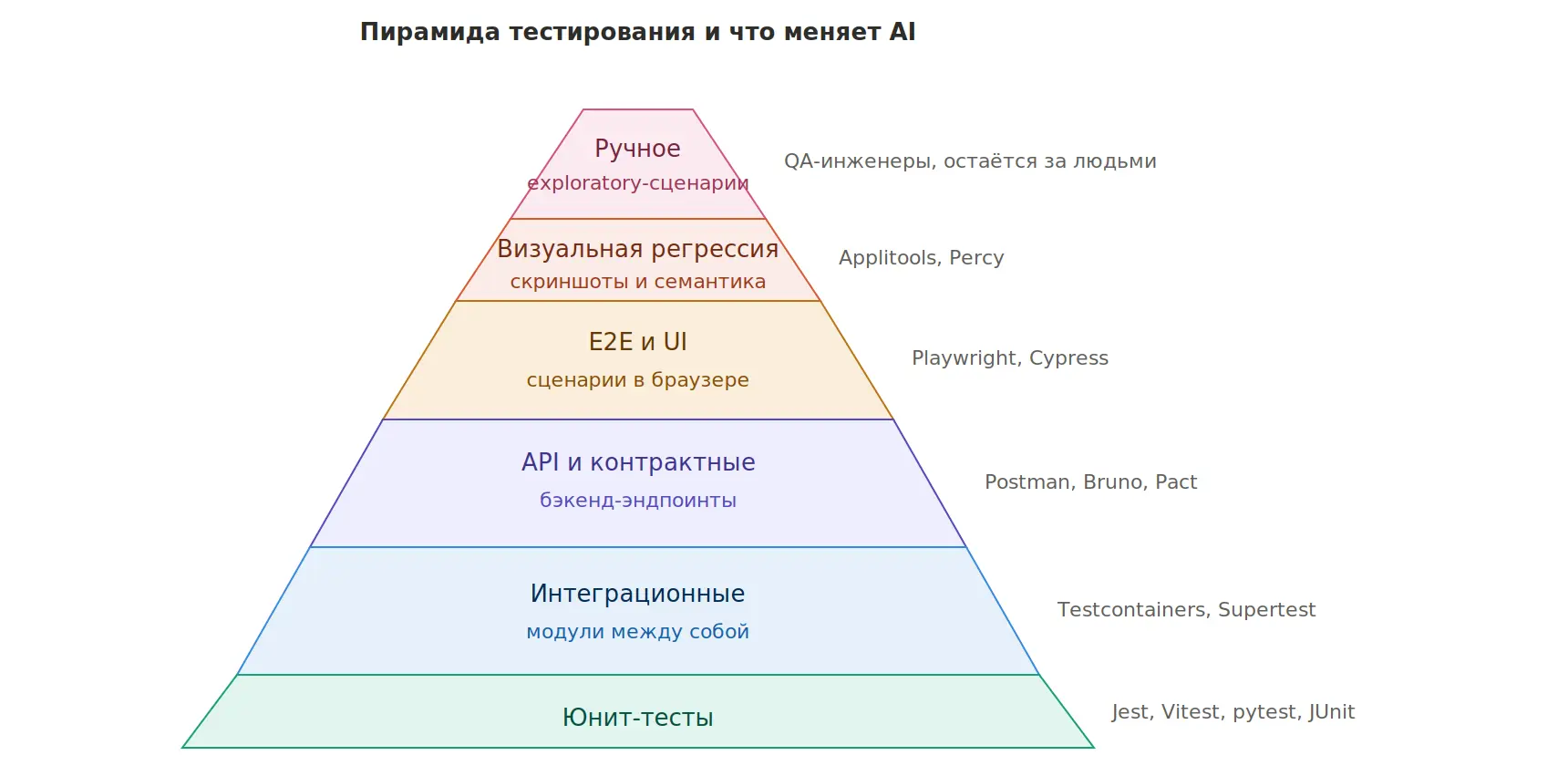
Дополнительно стоят два класса, которые в классическую пирамиду не вписываются: нагрузочное тестирование (k6, Locust, Gatling) и новый класс — тестирование AI-агентов, о котором отдельный раздел ниже.
Общее правило 2026 года: AI-агенты эффективнее всего работают на детерминированных нижних уровнях пирамиды (юнит, интеграционные, API) и на среднем уровне (E2E через self-healing селекторы). Верхние уровни — exploratory-тестирование и оценка пользовательского опыта — по-прежнему требуют человека.
У каждого уровня — своя экономика. Юнит-тесты дешёвы в написании и быстры в прогоне, но проверяют только отдельные куски кода. E2E-тесты дают уверенность в работе продукта целиком, но медленные и дорогие в поддержке. Между ними — интеграционные и API-тесты, которые дают лучшее соотношение уверенность/стоимость. Классический совет Мартина Фаулера — 70% юнит, 20% интеграционных, 10% E2E — в агентной разработке смещается: юнит-тестов становится ещё больше (они практически бесплатны), E2E — меньше, но осмысленнее. Нижний слой раздувается без видимых издержек, верхний сжимается до критических флоу.
Отдельный вопрос — когда тестирование мешает, а не помогает. На ранних стадиях продукта, когда продукт-маркет-фит не найден и каждую неделю меняется модель данных, полноценное тестирование съедает время, которое правильнее тратить на гипотезы. Разумный компромисс — минимальное покрытие критических путей (авторизация, оплата, сохранение данных), остальное оставить без тестов до стабилизации. С переходом в фазу роста тесты становятся обязательными. Агентная разработка смягчает эту дилемму: цена написания тестов падает настолько, что пропускать их теряет смысл даже на ранних стадиях.
TDD возвращается
Test-driven development двадцать лет существовал скорее как манифест, чем практика. Классический цикл «red → green → refactor» требовал писать тест до кода, и в продакшн-командах это воспринималось как дорогая дисциплина: тест пишется, сразу падает, потом пишется минимальный код, потом рефакторинг. В индустрии этот подход использовали единицы — обычно в финтехе и критичных системах, где стоимость ошибки оправдывала дополнительное время. На моей памяти TDD входил в каждый учебник по software engineering, но не входил в каждый реальный репозиторий.
С массовым приходом AI-ассистентов экономика изменилась. Тест из дополнительной нагрузки превратился в самый точный способ описать задачу для агента. Как формулирует Tweag Agentic Coding Handbook: «чем точнее промпт — а тест и есть самый точный промпт — тем качественнее генерация». Addy Osmani в обзоре своего workflow на 2026 указывает TDD как базовую практику агентной разработки, а не как опциональную дисциплину.
Почему это снижает галлюцинации. LLM без ограничений придумывает имена методов, сигнатуры, ссылается на несуществующие библиотеки. Тест задаёт жёсткий контракт: для таких входов — такой выход. Модель вынуждена сходиться к этому контракту, а не импровизировать. Eric Elliott в разборе AI-driven development прямо называет TDD «защитой от галлюцинаций» — тесты работают как заданные пользователем guard rails, ограничивающие пространство решений агента. Похожий эффект дают статически-типизированные языки: по наблюдениям практиков, Go и TypeScript с их строгой типизацией ловят часть галлюцинаций на этапе компиляции. TDD и типы дополняют друг друга — один контролирует поведение, другой структуру.
Механика в агентной разработке. Разработчик формулирует поведение в виде тестов (часто с помощью того же агента), проверяет тесты на адекватность, запускает агента писать код. Агент гонит тесты, получает ошибку, итерирует. Цикл «red → green → refactor» полностью исполняет сам агент — человек подключается только на верификации тестов и ревью итогового кода. Типичная сессия: 10 минут на проверку сгенерированных тестов, 0–5 минут наблюдения за работой агента, 5 минут на финальное ревью.
Ограничение. Исследование TDAD (март 2026) замерило: на слабых моделях TDD-промптинг увеличивает регрессии на 9,94%. Маленькие локальные модели теряются в процедурных инструкциях и ломают уже работающий код. На Claude Sonnet, GPT-5 и моделях сопоставимого класса эффект обратный — resolution rate растёт с 12% до 60% в автономных циклах с нулевой регрессией. Правило: TDD-агентный workflow имеет смысл только на сильных моделях.
Важный нюанс. Не стоит отдавать одному агенту и тесты, и код одновременно. Агент подгонит тесты под первое попавшееся решение, включая ошибочное. Rupeshit Patekar описывает это прямо: «если наивно дать AI писать и код, и тесты, он может сгенерировать тесты, которые валидируют ошибочное поведение». Правильный паттерн — сначала генерируются и проверяются тесты (желательно человеком или отдельной сессией), потом отдельная сессия пишет код.
Что изменилось для разработчика. До AI: тест писался из-под палки, часто постфактум, «для галочки». Качество покрытия было плохим — разработчик, закончивший фичу, не мотивирован искать собственные баги. В agent-driven TDD роли меняются: разработчик становится ревьюером тестов и верификатором кода, а не автором того и другого. Это освобождает когнитивный ресурс — человек сосредотачивается на том, что именно должна делать система, а не на том, как это написать. Тесты превращаются из побочного продукта в основной артефакт, с которым работает команда: это спецификация, критерий успеха и документация одновременно.
Побочный эффект — закрытие техдолга. Для зрелых команд, которые годами существовали с большим долгом по тестам, 2026 стал редким шансом этот долг закрыть. Не переписывать всю suite руками, а поручить агенту сгенерировать тесты для критических модулей за пару недель. Команды, которые раньше экономили на тестах, получают возможность догнать — и не исключено, что обогнать — тех, у кого тесты были, но устарели. Дисциплина перестала быть дорогим преимуществом, потому что больше не требует человеческого времени в прежнем объёме.
Юнит- и интеграционные тесты
Базовый слой пирамиды. Проверяет отдельные функции, классы, модули. В этой области AI-агенты дают наибольший выигрыш: код обозрим, зависимости изолированы, обратная связь быстрая.
Механика. Агент читает функцию, генерирует тесты на основные сценарии, edge cases, обработку ошибок. В агентной среде это часть TDD-цикла: агент сам пишет тесты из спецификации, получает их аппрув, пишет код, гонит тесты, итерирует до зелёного статуса. Для интеграционных тестов — тот же паттерн, но с настройкой окружения (тестовая БД, моки внешних сервисов).
Ограничения. Агент плохо находит edge cases, не описанные в требованиях. Доменные нюансы — специфика валют, временных зон, регуляций, отраслевых правил — требуют ручной доработки. Property-based тесты (проверка инвариантов на случайных входах) агент генерирует неуверенно: сложно формализовать, какие свойства должны выполняться.
Отдельный риск — агенту легко сгенерировать тесты, которые технически проходят, но ничего не проверяют: assertion на тип возвращаемого значения вместо проверки корректности, проверка что функция не бросила исключение, проверка что результат не null. Покрытие растёт, качество — нет. Это ловится через mutation testing: если изменение в коде не ломает ни один тест, значит тесты не проверяют эту логику. Метрика mutation score — честнее обычного coverage и стоит включения в CI для команд, которые серьёзно занимаются качеством.
Библиотеки. JavaScript и TypeScript — Jest, Vitest (быстрее Jest, нативный ESM), Mocha. Python — pytest (де-факто стандарт), unittest из стандартной библиотеки. Java — JUnit 5, TestNG. C# — xUnit, NUnit. Для моков — MSW (сетевые запросы), sinon (JS), pytest-mock (Python). Для интеграционных тестов с реальными зависимостями — Testcontainers (поднимает Docker-контейнеры с БД и сервисами прямо из теста). Для property-based testing — fast-check (JS), Hypothesis (Python).
Специализированные инструменты. Qodo (бывший CodiumAI) — генерация тестов по функции с явным анализом edge cases и mutation testing. Diffblue — Java-специфичный, работает с байт-кодом, не с исходным кодом. Meticulous записывает реальные продакшн-сессии и превращает их в regression-тесты — подход, который в 2026 всё чаще заменяет ручную поддержку E2E-тестов для критических флоу.
Типичный агентный workflow. Разработчик пишет одну строчку — «добавь функцию расчёта скидки по промокоду». Агент в TDD-режиме запрашивает уточнения: какие типы промокодов, какая максимальная скидка, что с уже применёнными акциями. На основе ответов генерирует тесты: базовый случай, процентная скидка, фиксированная сумма, превышение лимита, комбинация с распродажей, несуществующий промокод, просроченный промокод. Разработчик ревьюит тесты — 3–5 минут. Запускает агента писать реализацию. Агент пишет код, прогоняет тесты, видит падение в одном, правит, прогоняет снова, доводит до зелёного. Разработчик ревьюит итоговый код — 5 минут. Суммарное время на функцию — 15 минут вместо часа в классическом подходе.
API и контрактные тесты
Средний уровень пирамиды со стороны бэкенда. Проверяет, что эндпоинты отвечают ожидаемо, возвращают корректные коды ошибок, соблюдают контракт с потребителями.
Механика. Агент читает OpenAPI или GraphQL-схему и генерирует тесты для каждого эндпоинта: позитивные сценарии, обработка ошибок, валидация схемы ответа, проверка authz-правил. Для контрактных тестов — проверка соответствия между producer'ом и consumer'ом API: когда сервис A вызывает B, контракт фиксируется с обеих сторон, и любое изменение ловится при следующем деплое.
Ограничения. Бизнес-логика в API по одной схеме не восстанавливается. Сложные workflow-переходы (например, заказ может перейти из статуса «оплачен» в «отменён» только в течение часа и только администратором) требуют ручного описания. Агент сгенерирует тесты на соответствие схеме, но не на корректность бизнес-правил.
Библиотеки. Postman, Bruno (open-source альтернатива Postman), Insomnia — для ручного и автоматизированного API-тестирования. Для кода: REST Assured — Java-стандарт, Supertest — JS/TS, pytest-httpx или respx — Python. Для контрактного тестирования — Pact (де-факто стандарт). Schemathesis — property-based тесты на основе OpenAPI-спеки: автоматически находит эндпоинты, которые возвращают невалидные по схеме ответы.
Инструменты. Для агентной генерации API-тестов достаточно Claude Code или Cursor с доступом к схеме — отдельный AI-слой поверх API-тестирования пока не оформился в отдельный рынок, в отличие от UI-тестов. Это ожидаемо: у API тесты детерминированнее, селекторы не ломаются, self-healing здесь не нужен.
Контрактное тестирование — тихий герой 2026 года. В микросервисной архитектуре главная боль — рассинхронизация между producer'ом и consumer'ом API. Команда A меняет формат ответа, команда B узнаёт об этом по упавшим тестам в продакшене. Pact решает это через consumer-driven contracts: B описывает, что ожидает от A, A проверяет, что его изменения не ломают этот контракт. В агентной среде контракт генерируется из реальных вызовов: агент наблюдает, как B использует API A, и предлагает Pact-контракт. Раньше на это уходили недели ручной работы — теперь дни.
E2E и UI-тесты
Самый заметный сдвиг 2026 года — в E2E. По данным ThinkSys 2026, Playwright впервые обошёл Selenium по adoption — 45,1% против 22,1%. Cypress держит 14,4%.
Механика. Классический подход: разработчик пишет селекторы (page.click('#submit-btn')), и при любом изменении DOM тест ломается. Инженер тратит 30–40% спринта на починку селекторов после UI-рефакторингов. Новый подход: AI-слой поверх Playwright интерпретирует намерение («нажми кнопку Submit»), находит элемент по accessibility tree, автоматически обновляет селектор. По бенчмаркам Microsoft, Healer agent в экосистеме Playwright закрывает 75% сбоев по селекторам без участия человека. Оставшиеся 25% — логические баги и backend-изменения — требуют ревью.
Что сместилось в инфраструктуре. Playwright в 2026 — не просто фреймворк, а MCP-сервер, который подключается к AI-агенту. Codegen записывает пользовательские действия и генерирует тесты на основе accessibility-дерева, а не пиксельных координат или CSS-селекторов. Это означает: тест, записанный через Codegen, продолжит работать после смены дизайн-системы или CSS-рефакторинга, если семантика элементов сохранилась.
Ограничения. Self-healing работает на уровне селекторов и DOM. Логические баги (изменилась бизнес-логика, а не UI) и backend-изменения по-прежнему требуют ревью. Полностью автономная генерация E2E-тестов без ревью пока не работает: агент создаёт технически рабочие, но часто бессмысленные сценарии, которые проходят, но ничего осмысленного не проверяют — например, заполняет форму произвольными данными и проверяет, что страница не упала, не проверяя сам результат отправки.
Библиотеки. Playwright — стандарт 2026 для новых проектов: бесплатная параллелизация, trace viewer, MCP-интеграция, поддержка JS/TS, Python, Java, C#. Cypress — если команда уже использует и критичен time-travel debugger (пошаговый просмотр снапшотов DOM). Selenium — для legacy-суитов и polyglot-команд с поддержкой Ruby, PHP, Kotlin. WebdriverIO — максимальная гибкость для нестандартных сценариев (гибридные мобильные приложения, embedded-системы).
Инструменты с AI-слоем. Momentic, Reflect, Mabl, Rainforest QA — no-code платформы с self-healing, подписочная модель. Octomind, ZeroStep, Auto Playwright — open-source и semi-open решения поверх Playwright. TestDino — analytics и flaky test detection. Shiplight AI, Decipher — intent-based подход: описываете «что проверить», а не «как проверить». Для Playwright-native AI-стека — Codegen и встроенный Healer agent от Microsoft.
Практический расклад. Для команды до 10 разработчиков, которая строит E2E-покрытие с нуля, имеет смысл начинать с чистого Playwright и встроенных MCP-инструментов. Добавлять AI-слой стоит, когда команда ловит рост flaky-тестов и начинает тратить на их починку больше 20% времени в спринте. Для корпоративных команд с большой существующей suite на Selenium или Cypress правильная стратегия — не миграция, а обёртка: self-healing через Shiplight, Mabl или аналогичные инструменты работает поверх существующих тестов без переписывания.
Визуальная регрессия
Отдельный класс тестирования на стыке фронта и UX. Проверяет, что после изменения кода интерфейс не развалился визуально: шрифты, отступы, расположение элементов, цвета.
Механика. Агент сравнивает скриншоты до и после изменений, отличает значимые различия от шума (антиалиасинг, разные шрифты в CI-окружении, динамический контент вроде времени на странице). Современные решения используют не пиксельное сравнение, а семантическое: идентифицируют компоненты через DOM или accessibility tree и проверяют их визуальную целостность. Это снимает большую часть false positives классического pixel-diff подхода.
Ограничения. Динамический контент (даты, A/B-варианты, персонализация, рекламные блоки) требует маскирования вручную. Кроссбраузерные различия в рендеринге создают шум, который настраивается через baseline'ы для каждого браузера. Визуальная регрессия не ловит логические баги — пустая страница с правильной вёрсткой пройдёт тест.
Инструменты. Applitools — лидер корпоративного сегмента, собственные vision-модели для семантического сравнения, интеграция со всеми популярными E2E-фреймворками. Percy (часть BrowserStack) — интеграция с CI, снепшоты для каждого PR. Chromatic — специализирован под Storybook и компонентное тестирование, стандарт для дизайн-систем. Lost Pixel — open-source альтернатива, self-hosted.
Когда это критично. Визуальная регрессия даёт основной выигрыш в продуктах с богатым UI и большой дизайн-системой: SaaS-продукты, e-commerce, медиа-платформы. Для admin-панелей и внутренних инструментов добавляет шума больше, чем пользы. Хороший индикатор — есть ли в команде выделенный дизайнер, который регулярно вносит визуальные правки. Если да, визуальная регрессия экономит недели ручного QA. Если нет — можно отложить.
Снимаем false positives через правильную настройку. Основная боль визуальной регрессии — ложные срабатывания из-за шумового сигнала: сдвинулся на 1 пиксель отступ, шрифт в CI-окружении отрисовался чуть иначе, вторичный элемент закрыл часть компонента. Современные инструменты умеют игнорировать такие различия, но требуют настройки: указание игнорируемых регионов, задание порога чувствительности, маскирование динамического контента (даты, имена пользователей, счётчики). Без настройки команда быстро устаёт от потока «изменений», начинает машинально аппрувить всё подряд, и смысл тестов теряется.
Нагрузочное тестирование
В классическую пирамиду не вписывается, но в продуктах с заметным трафиком — обязательная часть тестового стека. Проверяет, что система выдерживает ожидаемую и пиковую нагрузку, где находятся узкие места, как деградирует производительность.
Механика. Сценарии имитируют реальное поведение пользователей: авторизация, просмотр каталога, оформление заказа. Запускаются с тысячами виртуальных пользователей, метрики собираются в дашборды: время отклика, пропускная способность, частота ошибок. AI-агент помогает на двух этапах — генерация сценариев из логов продакшена (вместо ручного описания) и анализ результатов (выявление аномалий, корреляция с деплоями).
Ограничения. AI-слой здесь пока скромнее, чем в E2E или юнит-тестах. Основная работа — сбор метрик и их интерпретация — остаётся за инженерами. Self-healing сценарии не нужны, потому что они не завязаны на UI-селекторы.
Инструменты. k6 (Grafana, open-source, скрипты на JS) — стандарт для новых проектов. Locust (Python) — когда нужна гибкость. Gatling (Scala) — для высоких нагрузок и детальных отчётов. JMeter — старый стандарт с большим ecosystem плагинов. Для облачного запуска — k6 Cloud, BlazeMeter, Artillery.
Когда это нужно. Нагрузочное тестирование оправдано, когда у продукта есть предсказуемая аудитория и понятные SLA. Для B2B-SaaS со стабильным ростом — обязательно: один крупный клиент, начавший использовать продукт в прайм-тайм, способен положить систему, если её пиковая нагрузка не протестирована. Для ранних продуктов с нестабильным трафиком — опционально, первые тесты имеет смысл провести перед маркетинговой кампанией или крупным запуском. AI-слой здесь помогает генерировать реалистичные сценарии из логов вместо искусственных шаблонов — это главное, что изменилось за 2024–2026 годы.
Тестирование AI-агентов
Отдельный класс тестирования. Обычные unit-тесты здесь не работают: агент недетерминирован, один и тот же запрос к одной и той же модели может дать разный результат из-за температуры семплинга, длины контекста, порядка tool calls. Проверка «input → assert equals output» здесь неприменима — ответ может быть семантически правильным, но текстуально разным. Тестирование строится на четырёх слоях.
Offline-оценка на датасете. Заранее подготовленный набор запросов с ожидаемыми результатами. Проверяется итоговый ответ (агент дошёл до цели), промежуточные решения (выбрал правильный инструмент с правильными параметрами), успешность tool calls (вызовы не падают по ошибке). Метрики — не бинарные pass/fail, а распределения: в каком проценте случаев агент сходится, средняя длина цикла, стоимость за решение. Основной рабочий слой на этапе разработки и до каждого релиза.
Online-мониторинг в продакшене. Трассировка реальных запросов в агентной системе: каждый шаг цикла, каждый tool call, каждый ответ модели. Метрики качества, cost per request, задержка, доля эскалаций к человеку, доля «застрявших» сессий (агент превысил лимит итераций). Агрегируется в дашборды, алерты при аномалиях. Без online-мониторинга невозможно понять, что агент в продакшене ведёт себя не так, как на eval-датасете.
Regression после изменений. Каждое изменение промпта, модели или инструмента — это потенциальная регрессия. Прогон на eval-датасете до и после изменения, сравнение метрик. Если доля правильных ответов упала хотя бы на 1–2%, изменение не катится. Версионирование eval-датасета здесь критично: без него непонятно, что именно сравнивается.
Adversarial и red-teaming. Проверка агента на вредные входы: prompt injection (попытки перезаписать системный промпт), утечка конфиденциальной информации, обход ограничений, jailbreak через ролевые игры. Для агентов с доступом к корпоративным данным или финансовым операциям это не опциональный слой, а обязательный. Отдельный датасет с атаками, отдельная команда, которая его пополняет.
Паттерн LLM-as-judge. Когда нет объективного «правильного ответа», одна модель оценивает ответ другой по критериям. Работает для субъективных метрик — тон, релевантность, полезность, соответствие брендовым гайдлайнам. Не работает для фактических проверок: judge-модель склонна повторять ошибки основной модели, особенно если они из одного семейства. Правило — использовать для judge другое семейство моделей: если основной агент на Claude, judge на GPT, и наоборот.
Библиотеки и платформы. Promptfoo — open-source eval-фреймворк, работает как YAML-конфиг с датасетами и assertion'ами. Inspect AI — от UK AI Safety Institute, стандарт для safety-evaluation. DeepEval — eval-фреймворк в формате pytest, привычный для Python-разработчиков. Для платформ с observability + evals: LangSmith (от LangChain), Langfuse (open-source), Braintrust. Для adversarial-тестирования: PyRIT от Microsoft и Garak от NVIDIA — оба open-source, содержат библиотеки известных атак.
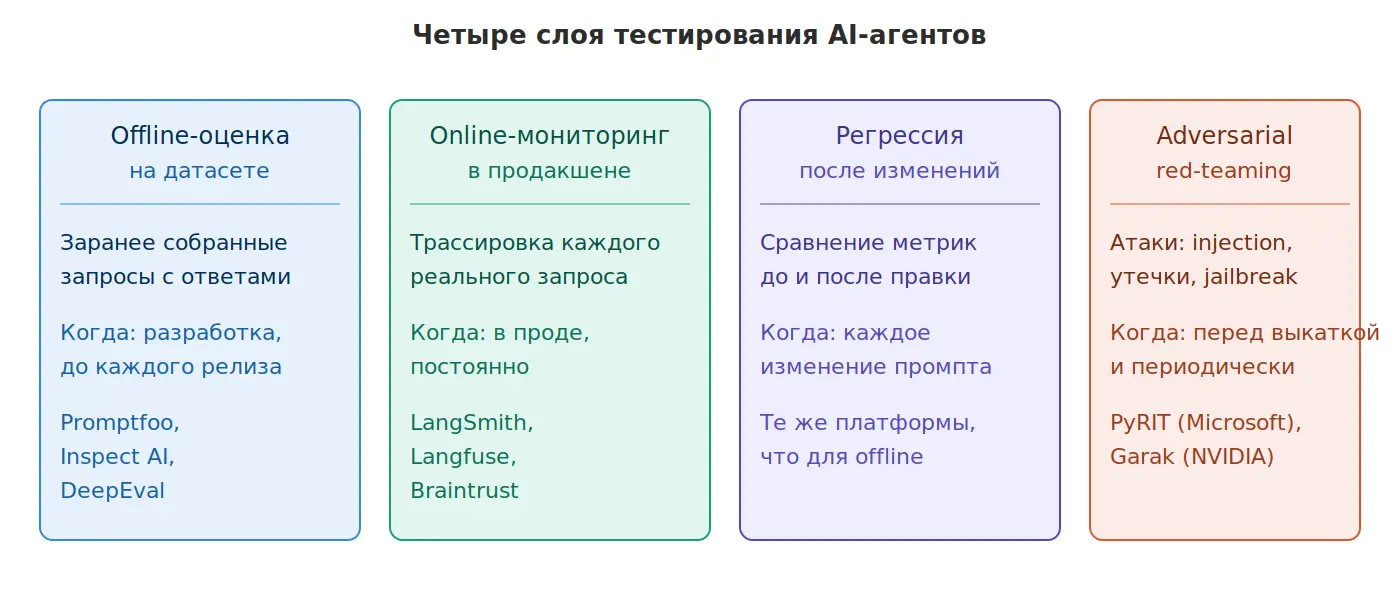
На практике команды часто начинают с offline-слоя и останавливаются на нём — это ошибка. Без online-мониторинга непонятно, что агент в реальном использовании ведёт себя иначе, чем на синтетических примерах из датасета. Без регрессии каждое изменение промпта превращается в рулетку. Без adversarial-слоя продукт уязвим к атакам, которые сейчас стандартная часть ландшафта угроз для LLM-продуктов.
Стоимость этой работы. Подключить eval-фреймворк и собрать стартовый датасет из 50 примеров — день работы одного инженера. Поднять observability-платформу и подключить трассировку — два-три дня. Собрать содержательный adversarial-датасет — неделя. Итого меньше двух недель, чтобы закрыть все четыре слоя на базовом уровне. Отсутствие любого из них в AI-first продукте — не вопрос бюджета, а вопрос зрелости процессов.
Среды для агентной работы с тестами
Cursor, Claude Code, Aider — это не инструменты тестирования, а среды, в которых вся описанная выше работа складывается в единый цикл. Они оркестрируют TDD-loop: агент пишет тест, запускает его, получает ошибку, чинит код, перезапускает, доводит до зелёного.
Aider исторически ближе всех к TDD — автоматически гоняет тесты после каждой генерации кода и откатывает изменения при падении. Встроенная git-интеграция: каждая итерация — отдельный коммит, откат в один клик. Работает из терминала, требует минимум настройки. Популярен у разработчиков, которые хотят максимум контроля и минимум абстракций.
Claude Code — через систему hooks и skills подключает произвольные pre/post-коммиты и тестовые команды. Тесты запускаются до и после изменений, результаты попадают обратно в контекст. Сильная сторона — работа с большими репозиториями через встроенный поиск и умение работать с целыми directory trees одной командой. Интегрируется с VS Code, JetBrains IDE, работает автономно в терминале.
Cursor — agent mode с YOLO-режимом для автономного прогона тестов. Работает поверх любого фреймворка, но требует более точного описания workflow. Сильная сторона — IDE-like интерфейс, удобный для ревью генерируемого кода в реальном времени.
Выбор среды зависит от стиля работы команды. Разработчикам, которые живут в терминале и хотят точный контроль над каждым шагом, ближе Aider. Тем, кто работает в IDE с богатым GUI и регулярно переключается между задачами, — Cursor. Claude Code с его опорой на skills и hooks хорош для команд, которые уже построили свою внутреннюю методологию разработки и хотят зафиксировать её в переиспользуемых паттернах. Ни одна из сред не лучше остальных в абсолютном смысле — это вопрос соответствия инструмента привычкам команды.
Для продакшн-систем добавляется слой CI/CD: GitHub Actions (41% в корпоративном сегменте, по JetBrains State of CI/CD 2025), GitLab CI, CircleCI. AI-генерация тестов в IDE — только половина работы; регресс должен гнаться на каждый pull request. Важный паттерн 2026 года — preview-окружения для каждого PR с автоматическим прогоном E2E-тестов в реальном браузере. Сервисы вроде Vercel и Railway делают это за два клика, раньше требовалась кастомная инфраструктура.
Баланс стоимости и скорости. Полный прогон всех тестов на каждый commit быстро становится дорогим — и по облачным ресурсам, и по времени команды, которая ждёт CI. Стандартный паттерн: юнит-тесты на каждый push (быстро, копейки), интеграционные и API — при открытии PR, E2E и визуальная регрессия — при merge в main, нагрузочные — по расписанию раз в день или перед релизом. Такое разделение снижает латентность обратной связи для разработчика и одновременно удерживает стоимость инфраструктуры в разумных рамках.
Как внедрять
Восемь практических моментов, которые стоит учесть при переходе на агентную работу с тестами.
TDD с первого дня на новых проектах, постепенно — на старых. На новом коде агент пишет тесты до кода почти без дополнительной стоимости. На legacy-кодовой базе сначала покрывают критические модули (платежи, авторизация, экспорт данных), потом расширяют. Попытка переписать все тесты сразу — типичный путь к провалу: агент генерирует тысячи тестов, половина из которых бессмысленна, и команда тратит недели на ревью вместо продуктовой работы.
Не смешивать генерацию тестов и кода в одной сессии агента. Агент подгонит тесты под первое пришедшее решение, включая ошибочное. Правильный паттерн — сначала тесты (человек или отдельная сессия), потом код в другой сессии с фиксированным тестовым контрактом. На практике это означает две git-ветки или два чата: один для тестов, другой для реализации.
Измерять качество, а не покрытие. Высокое code coverage при агентной генерации достижимо за день, но не гарантирует, что тесты осмысленные. Метрики, которые стоит вести: mutation testing score (какая доля мутаций кода ловится тестами), доля тестов с осмысленными assertion'ами, частота ложных срабатываний в CI. Инструменты для mutation testing: Stryker (JS/TS), mutmut (Python), PIT (Java).
Версионировать eval-датасеты для AI-агентов. Датасет оценки — такой же артефакт, как код, с историей, ревью изменений, бранчами. Без этого через полгода неясно, почему метрика упала: модель стала хуже или датасет «дополнили» примерами, которые в старой версии ловились хуже. Практика — хранить датасеты в том же репозитории, что и код агента, с обязательным code review на любое изменение.
Ручное exploratory остаётся за QA-инженерами. AI плохо находит странные сценарии, которые не описаны в требованиях. Типичный пример — пользователь с устаревшей версией мобильного приложения, у которого отключены уведомления, меняет часовой пояс во время активной подписки. Такие сценарии ловят люди, не агенты. Освободившееся на автоматизации время команда направляет именно туда — на поиск неочевидных проблем, оценку UX, проверку пограничных случаев в доменной логике.
Self-healing окупается только при частых UI-изменениях. Если продукт стабилен и UI редко меняется, AI-слой поверх Playwright или Cypress даёт минимальный выигрыш при росте стоимости. По оценкам Perfecto 2025, self-healing экономит до 70% времени на поддержке — но только когда это время было значимой статьёй расходов. Для команд, которые тратили на поддержку 5% спринта, AI-слой добавит сложности без заметного выигрыша.
Тестирование AI-агентов начинать с online-мониторинга, а не с eval-датасета. Противоречит интуиции разработчика, но работает лучше. Без продакшн-данных eval-датасет собирается из синтетических примеров, которые часто не совпадают с реальным использованием. Правильный порядок: запуск в ограниченном продакшене с подробной трассировкой → сбор реальных расхождений и ошибок → формирование eval-датасета на основе этих случаев → регрессионные прогоны на нём для каждого изменения.
Не экономить на адверсарном тестировании, если агент трогает деньги или персональные данные. Prompt injection в 2026 году — не гипотетическая угроза, а реальный вектор атак на LLM-продукты. Агенты, которые могут делать возвраты, отправлять email, читать PII, обязательно проходят adversarial-слой до выкатки. Для команды без опыта безопасности проще всего взять готовые датасеты из PyRIT или Garak и прогнать их перед каждым мажорным релизом. Это не заменяет регулярное red-teaming, но закрывает базовый уровень.
Источники
- Addy Osmani — My LLM coding workflow going into 2026
- Eric Elliott — Better AI Driven Development with TDD
- Tweag Agentic Coding Handbook — Test-Driven Development
- arXiv: TDAD — Test-Driven Agentic Development (март 2026)
- ContextQA — Playwright vs Selenium vs Cypress 2026
- TestDino — Playwright AI Ecosystem 2026
- Vervali — Testing Tools Comparison 2026